
前情提要
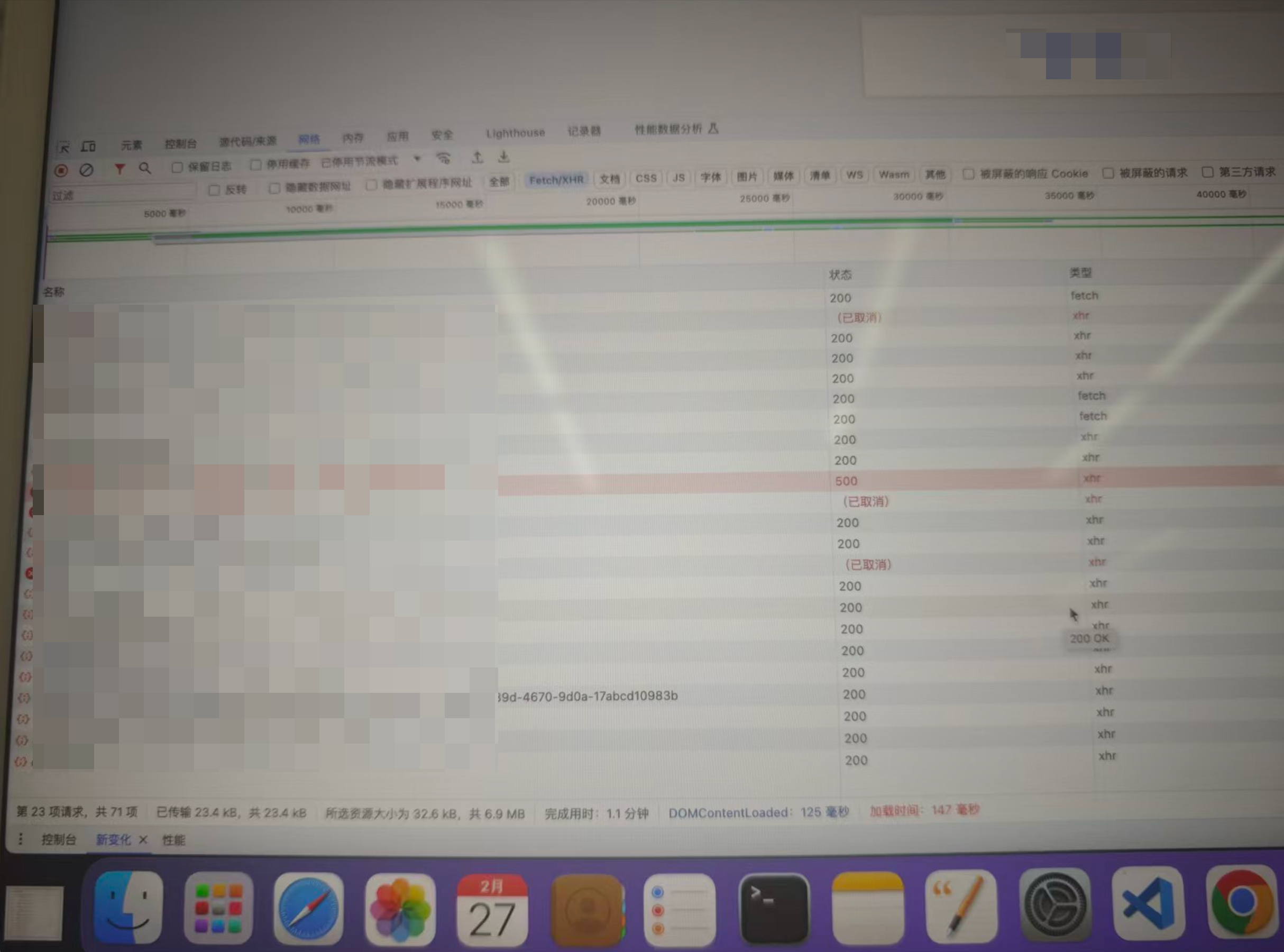
本周同事值班,昨天17:20收到私有化产品告警,客户反馈某功能页面未加载内容,控制台接口返回 500 错误。
根据用户反馈的截图来看,打开具体功能页面未加载部分内容,控制台相关接口500
同事第一时间和客户的对接人取得联系,由于客户服务器登陆需要申请审批,暂时无法登陆,先提上审批流程
大约过了5分钟,客户反馈页面恢复正常了
这里从前场上报客户反馈的问题到恢复只过去7分钟,由于客户已经恢复使用,登录服务器的流程就先不着急了,等客户申请好权限后我们在上去排查下根因,暂时约在第二天下午
今天下午,值班的同事请假了,我这边临时接受根因排查的工作
下午3点,客户准备好服务器登录权限后,我这边指导客户远程进行操作排查
由于客户性质原因,排查方式为和客户微信视频通话,客户举着手机摄像头对着电脑屏幕执行我发过去的他复制执行的命令
网络差、像素低、沟通困难、排查效率低
当然这些都是闲话,接下来进入正题
排查过程
一句话描述下部署架构:多节点的k3s集群运行我们的产品服务,持久化数据用集群外的nfs机器存储
首先查看业务集群pod状态
kubectl get podrocketmq broker重启了14次
describe看下具体内容
kubectl describe pod rocketmq-broker-0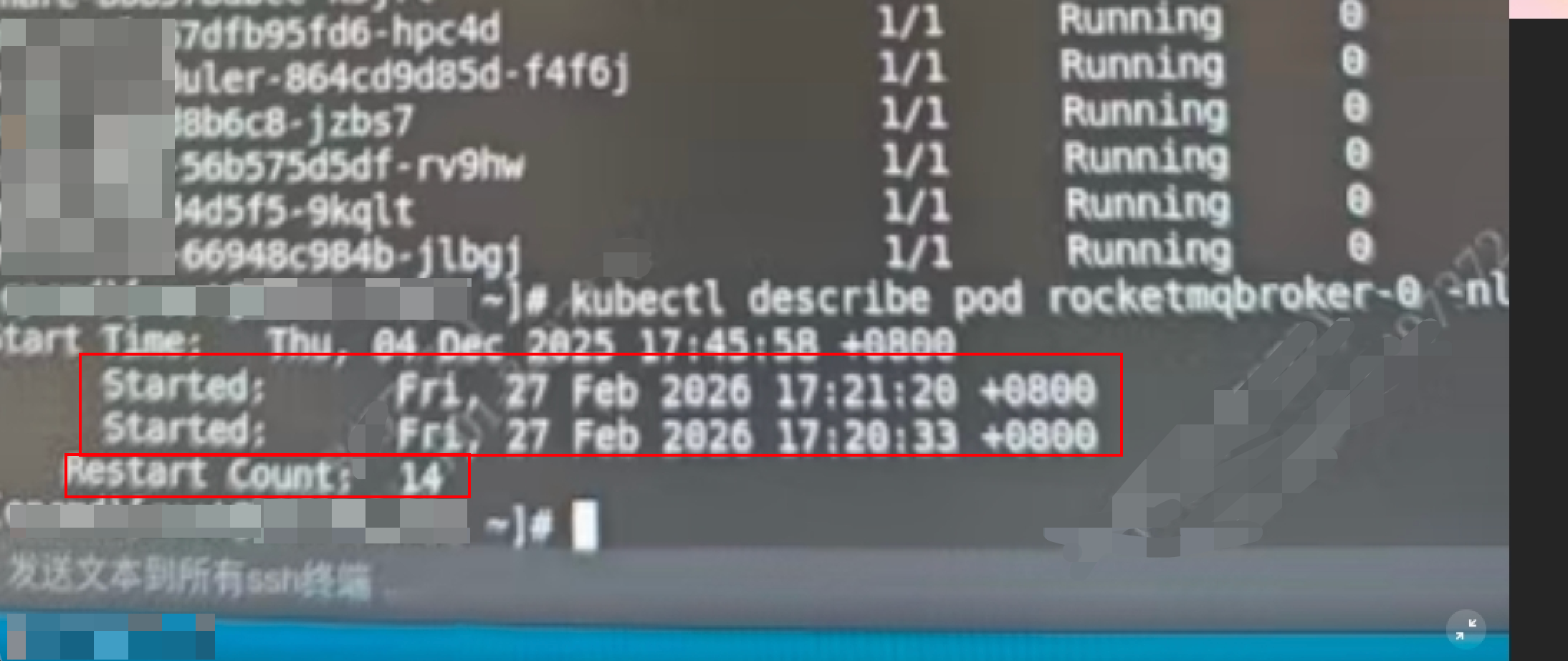
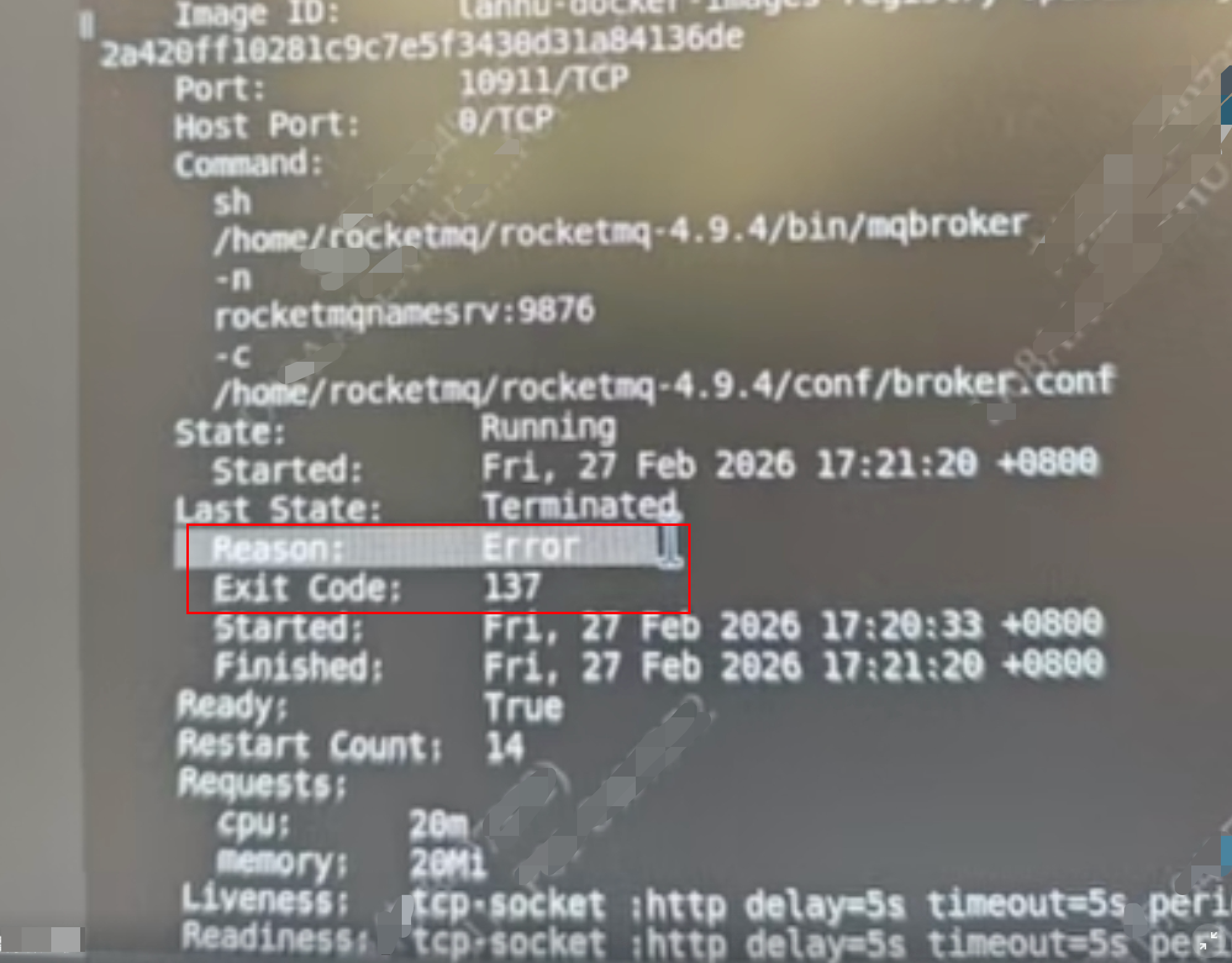
最近一次重启的时间是17:21,和故障时间吻合,几个关键信息:
Reason是error的
Exit code是137
重启前运行了47秒
继续排查上个容器的日志
kubectl logs -p rocketmq-broker-0-p参数查看pod的上一个容器
除了一条启动日志,没有任何其他日志,当前当前容器也是一样
exit code 137,大概率是oom被kill了
那就先确认下集群资源
kubectl top nodes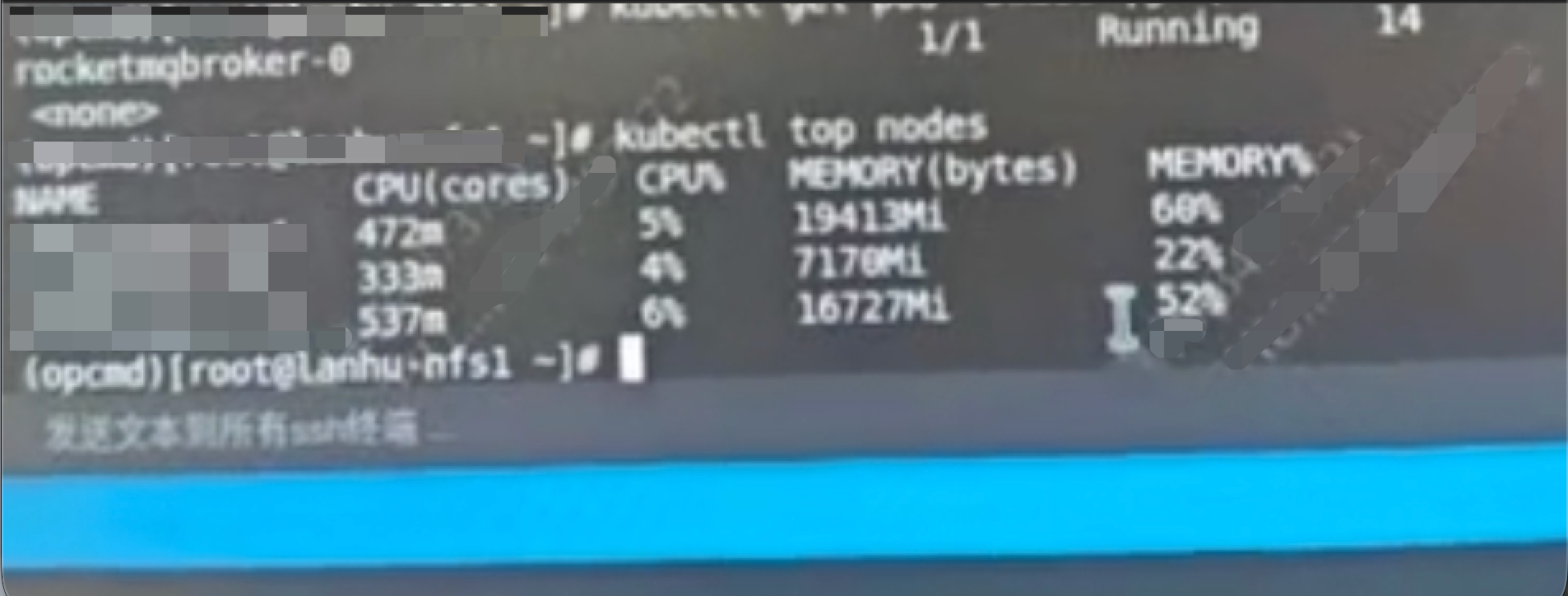
资源不紧张,这里大概结论:
pod没有资源limit限制,且集群资源使用率不高,pod因为oom被反复kill的可能不大
先登录到mq调度的节点上看下系统日志
dmesg -T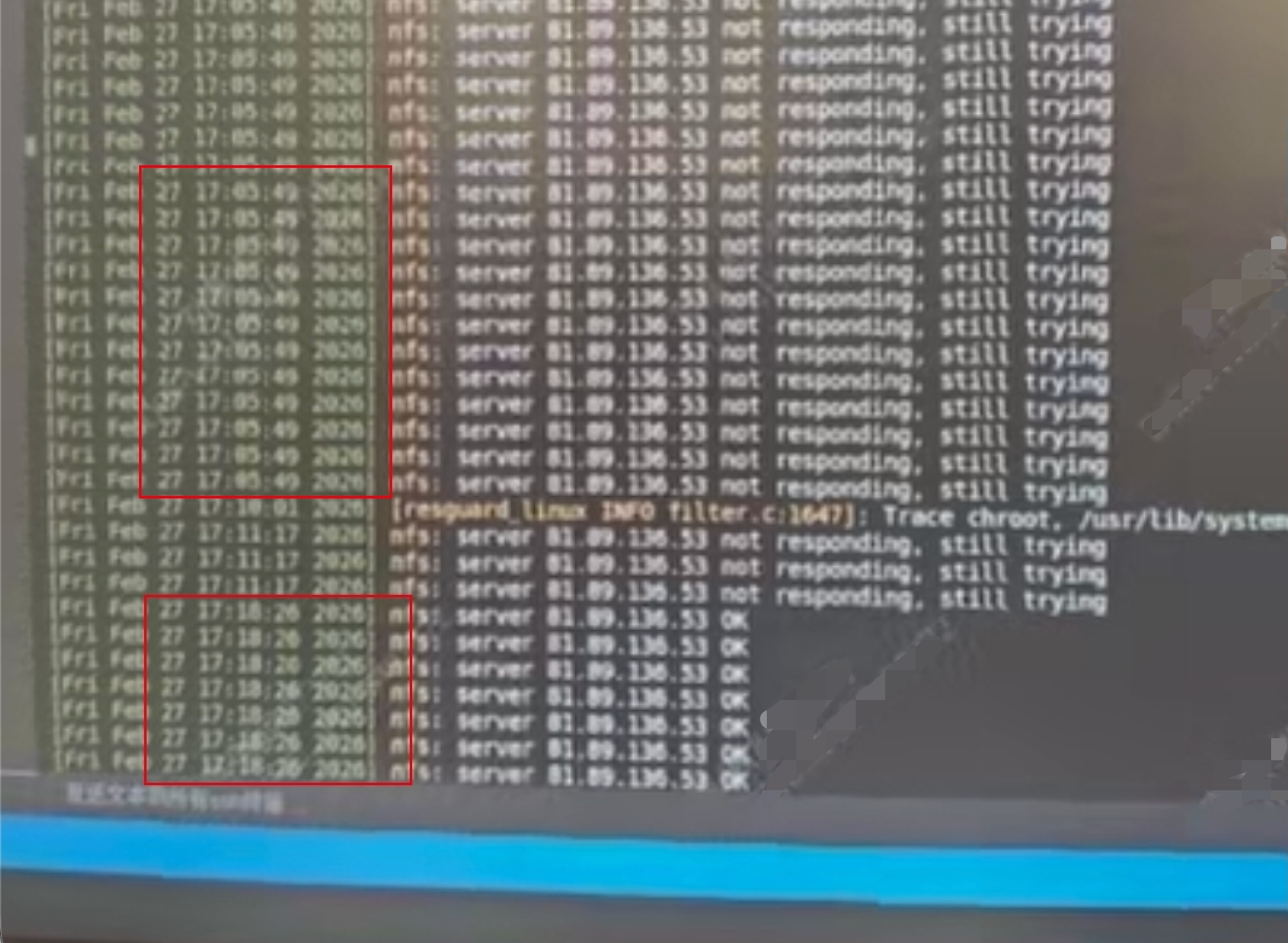
发现17:05开始该nodes连接nfs的网络有问题,直到17:18才恢复
同时没有看到oom的日志
这里基本可以退推断因为17:05至17:18期间rocketmq部署节点无法访问nfs,网络问题导致容器被存活探针强制重启。
因为客户问题暂时没有在遇到,同时视频远程的方式也不方便,就按照此结论和客户同步了,同时让客户帮忙和网络同事确认下故障时间的网络情况
随后也在团队内同步了改进论
思考复盘
事情告一段落后,在脑子里简单复盘了下故障排查的过程,觉得结论可能存在的两个challenge
怎么确认rocketmq是因为nfs连不上导致?为什么只有rocketmq-broker这个sts重启这么多次,其他的数据库、中间件没有这个情况
这里有一个猜想:
node到nfs节点的故障只有rocketmq-broker调度的这一台,这台上只调度了rocketmq-broker?
rocketmq-broker服务对于存储的依赖极强,出现问题会立即停止服务访问?
如何证明137是pod被livenessProbe失败触发的kubelet
没有查看kubelet日志,这里只能反向证明不是因为oom被kill掉,因为没有看到oom日志
另外这里顺便回顾了下exit sratus的知识点:
https://www.gnu.org/software/bash/manual/html_node/Exit-Status.html
bash官方的文档,当命令因一个编号为 N 的致命信号终止时,Bash 将 128+N 作为退出状态。
Exit code 137 = SIGKILL,128+9,也就是我们常用来强制终止进程的kill -9的9
这里在kubernetes情况下,pod被强制kill的情况通常为oom或livenessProbe失败
个人总结
自己简单梳理复盘后,觉得要解决以上challenge还是需要做对应的环境复现和测试才行
等后续有空在针对这个问题做个更深入的排查
这也提醒了博主,后续排查这种问题时候,思路需要更清晰,排查方向需要更清晰